

I created my own search engine from scratch
I built a whole search engine using only javascript and here is how

I am a developer from Nepal who loves playing with tech.
Recently I built a search engine from scratch. Yes, I didn't use code from any existing repository or from any youtube video. I mean, I created a bot that goes to every website and scrapes data from there, stores the data into the database, and from a MERN application with an accessible user interface, I can search the query. And it returns results in both text format and in image format.
Introduction
I think you already have an idea about my project. To describe it in short, I basically built a website with a search box where I can type anything and it returns something back to us. Yes, just like Google, Duckduckgo, Bing and Yahoo.
I am going to embed a video here which takes you thoroughly over the search engine I built.
I have deployed the search engine over a server. So you can access the website anytime. You can visit 143.198.136.81 to access the search engine. Still, I haven't got any domain name for this website. I think I will manage a domain name soon.
Project division
I had to divide the whole project into two separate projects. They were a bot and the MERN app itself. Imagine if I had the same project for both the bot and the search engine, the bot would have engaged in scraping the websites while the user is requesting data from the front end. Since the javascript is single-threaded and the system keeps busy processing the scrapped data, there would have been a higher delay in returning processing the request of the user and returning the result back.
Both to avoid such problems and to get the flexibility to host the bot and MERN app on a different server, I divide the search engine into two projects: Bot and MERN app.
1. 🤖The Bot
A bot is basically a program that automatically runs over and over again if the given condition is satisfied. I created a bot using javascript which goes over different websites and scraped the data from there. Then also process the data. More about the bot, we will discuss later in this article.
2. 💻The MERN app
Of course, a platform is needed from where a user can search their query and get the result back in a visual format. I have used javascript here also, (of course MERN stack is based upon javascript 😅).
🛠Tools I used
I used a single programming language to build this search engine and that programming language is javascript. And it is a language with which I am pretty comfortable. I used a javascript bot for the bot and the search engine. And I used two databases RedisJSON and MongoDB. Allow me to explain those tools in detail:
1. For the bot
To make the bot I had different choices like cheerio, jsdom with axios, fetch API, etc. But to index the website I had to look at the loading time of the website. So I choose to go with headless browsers in javascript. And the name that suddenly popped up in my mind was puppeteer. Let's have more discussions on all tools used to make a bot.
Puppetter -> It is the main library that I used for the bot. This library downloads a chromium browser and it can control the browser just like puppet. We can run the browser in both headless mode and non-headless mode. I used headless mode here for obvious reasons. Why do I need a GUI if the bot can do the same thing without showing up the window? And with puppeteer, I could wait for the page to fully load and execute all javascript code which enables me to scrape the Single Page Applications (SPAs). Also, I could keep track of loading time.
Redis-om -> I have used the RedisJSON database to save the scraped content and images. So I basically need a library to keep my bot connected with the database and allow it to perform functions there.
Mongoose -> I have used another database (MongoDB) to save the links that have been laid out on the scraped website. And the bot periodically fetches those links and crawls over them. And to keep the bot connected with the MongoDB database and perform CRUD operations, I used mongoose.
robots-txt-parser -> As a developer, you probably know that certain pages of our websites are not allowed to be indexed public on search engines. So to avoid the bot crawling over those pages, a robots.txt file is created. And using this package, I was able to know if I am allowed to crawl the page or not.
2. For MERN
This is a full-stack application where the user can search and get the results. It is obvious that if you know the full form of MERN, you know what packages I am going to use here. I need both databases here also. So, I definitely need to use mongoose and redis-om. Except these let's see what other libraries I used:
React -> React is a frontend javascript framework that allows us to make SPAs all using javascript. Yes, there you can see HTML-type-looking words which are JSXs.
Material-ui -> I have written a lot of custom CSS code myself. And my friend Roshan Acharya wrote more lines of CSS code than I did. Still, we had to use material-ui for some components and also for the icons. To be specific we used
@mui/icons-materialand@mui/material.Axios -> I had made an API on the backend so, I needed some tool to interact with that REST API. Of course, fetch API was there but I chose to go with Axios. Compatibility man :)
There are a lot of packages used with react. If you want to have a look then you can visit here. Otherwise, let's look at our server dependencies.
Express -> I used express.js to create a server, listen to some ports, and check if someone hits the endpoint or not. If any request comes, then it is processed and the result is sent back. In short, I made REST API with express.
joi -> As a developer, we don't trust users. They input anything so to validate the request, I have used the joi library.
How the search engine works⚙
To know about the exact working of the search engine, you can watch the video at this exact time. Anyway, I am going to explain the architecture and the flow of the request and response cycle here.
🛢️ Databases
Before explaining the architecture of the website, I want to clarify one thing the project is using three databases. They are to store the links, images, and scraped data of the website. Two of them are the RedisJSON database hosted on the Redis cloud and the third one is the MongoDB database from MongoDB Atlas.
Three phases
The whole process of the application can be divided into three phases:
- Crawling:
In the crawling phase, the bot visits the website and scrapes the data out from there. - Parsing:
Then in the parsing phase, the scraped data is processed and important content is stored inside of the database such that searching will be faster and more efficient. - Indexing:
And in the indexing phase, the user types the query, and the application search for the result from the database and shows the result according to the indexing algorithm.
Architecture
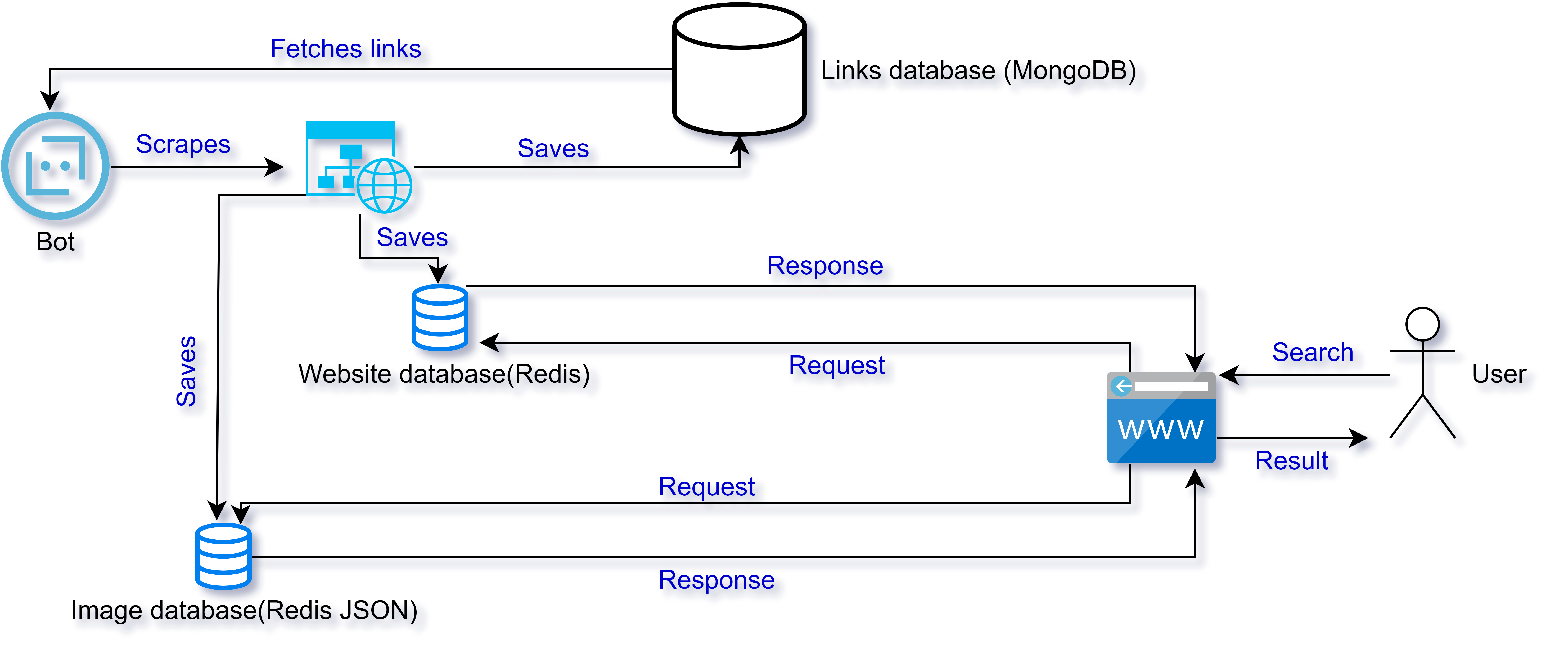
At first, the bot fetches the URL of the websites to be scraped from the database. The bot visits the website if crawling is enabled in the robots.txt file of the website and scrapes the data from there. The bot scrapes data from different sources within the page to know what the website is all about. It tracks the loading time of the website too. After the data is scraped from the website, the data is then parsed. The images are saved inside of the images database, the parsed content is saved inside of the websites database and the links that are found inside of the website are stored in the links database because the bot needs to visit those websites too. After all of the data is saved successfully, the bot fetches another link and the process continues. This is all done by a bot.
Now let’s see how the user can interact with the website. The user can request two things, one is to get the result of the search term they used (either in text format or image format) and the other is to request the bot to crawl their website in order to rank their website.
When a user searches for the query, a request is sent to the backend. The backend validates the query and looks for the result in the database. If the request is to search images then the backend looks inside the images database otherwise the backend searches in the websites database. If any result is found, the result is then manipulated and presented to the user according to the indexing algorithm. And if the user is requesting to crawl their website then the URL of the website is stored inside of the links database in order to let the bot know that the link exists.
🧮 Indexing algorithm
I have talked a bit more about the indexing algorithm. Let’s see the algorithm. The algorithm takes account of three things, how many times the website is referred inside of another website (backlink), the loading time of the website(Load Time) and the last updated date of the website with the backlink having the most priority, the load time having medium priority and the last updated data having the least priority.
Learnings 📝
There are many things to learn while building your own search engine from scratch. Yes, I have built the search engine and that is why I am saying such a thing. First of all you are not provided a lot of resources that can guide you and give you a little perspective of what you are going to do. Anyway, I found a really good guide from Google itself on how the google search works.
I didn't know which tools and languages to select so I had to build my own tech stack. Yes, it is a simple tech stack. One of the most important issues I faced was running the puppeteer on a linux server. Anyways I figured out the solution and deployed the bot.
One important incident I want to share here. When I used to search for anything related to search engines, I was always greeted with search engine optimization results. From there I knew which HTML tags to target to get the page content and how to scrape the website. I mean I kind of reverse-engineered there.
There are certainly more issues I faced. As a developer, I am used to with those pain. But I shared my main takeaway form this search engine project. Soon, I will write a complete guide on how to make your own search engine here. Till then, bye.
Some links
At last, I want to lay down some links for you who is reading to help out:
- GitHub repository of MERN part of search engine
- GitHub repository of the Bot of search engine
- The search engine itself
- Try searching Space
- The video explaining the project
- Message me if you have any problems
Good news guys I have managed a domain name. Here you go https://www.juhu.live/.



